VMware vSphere VMFS is a high-performance cluster file system (CFS) that enables virtualization to scale beyond the boundaries of a single system. Designed, constructed and optimized for the virtual infrastructure, VMFS increases resource utilization by providing multiple virtual machines with shared access to a consolidated pool of clustered storage. And it offers the foundation for virtualization spanning multiple servers, enabling services such as virtual machine snapshots, VMware vSphere Thin Provisioning, VMware vSphere vMotion, VMware vSphere Distributed Resource Scheduler (vSphere DRS), VMware vSphere High Availability (vSphere HA), VMware vSphere Storage DRS and VMware vSphere Storage vMotion.
VMFS reduces management overhead by providing a highly effective virtualization management layer that is especially suitable for large-scale enterprise datacenters. Administrators employing VMFS find it easy and straightforward to use, and they benefit from the greater efficiency and increased storage utilization offered by the use of shared resources.
This paper provides a technical overview of VMFS, including a discussion of features and their benefits. It highlights how VMFS capabilities enable greater scalability and decreased management overhead and it offers best practices and architectural considerations for deployment of VMFS.
http://www.vmware.com/files/pdf/vmfs-best-practices-wp.pdf
feedproxy.google.com [X] <http://feedproxy.google.com/~r/Ntpronl/~3/R5-ttn8oiHs/2226-Technical-White-Paper-VMware-vSphere-VMFS-Technical-Overview-and-Best-Practices.html>
◆
________________________________
Original Page: http://feedproxy.google.com/~r/Ntpronl/~3/R5-ttn8oiHs/2226-Technical-White-Paper-VMware-vSphere-VMFS-Technical-Overview-and-Best-Practices.html
Sent from Feeddler RSS Reader
Thursday, November 29, 2012
Wednesday, November 28, 2012
From the Bloggers Bench: Is VMware Site Recovery Manager Really Worth It? - VMware SMB Blog
Let's start off with a cheery fact 'the U.S. Department of Labor estimates over 40% of businesses never reopen following a disaster. Of the remaining companies, at least 25% will close within 2 years. Over 60% of businesses confronted by a major disaster close by two years, according to the Association of Records Managers and Administrators (information source<http://sbinformation.about.com/od/disastermanagement/a/disasterrecover.htm>).
A question I'm asked a lot is do I really need DR? Well reading the above statement, I hope the answer is yes, but in all reality the actual answer is, it depends. OK that is probably the most 'woolly' thing anyone in IT can say, we like hard and fast, black and white rules as engineers dammit!
For example, you may work for a company that has no on premise IT, you use a cloud based platform for your accounts, CRM and HR packages and you use hosted Exchange, SharePoint and Lync as your communication pieces, would you need DR, well the answer is probably not.
What about if you work for a company with a vSphere environment which can cater for two host failures and has redundancy on every level. This is then housed in a Tier 5 Datacenter offering 99.999% uptime, with the usual battery backed generators, diverse internet links, fire suppression systems and environmental monitoring. Connectivity is provided by diverse links to the datacentre, would you need DR then? Possibly as it depends on how the company views risk, if I was a betting man, I would say in most scenarios DR wouldn't be necessary.
Both of the above are extremes and most SMB require on premise solutions to facilitate how they work and often they don't have the budget to use datacentres and prefer to use remote offices for any DR activity.
So what does DR being with? Well two terms that you often hear banded about RTO and RPO, (great, I hear you say just what we need, more abbreviations in IT).
* Recovery Point Objective is the term used to describe how much data loss can be accepted. Let's imagine you have been working on an awesome vSphere design for the past week and you had finally nailed it, but before you hit save you get a BSOD. You are a good boy/girl scout and perform backups on a daily basis, which means that your RPO is daily.
* Recovery Time Objective is the term used to describe how long you are prepared to wait to restore data. So in the above scenario, you probably swear a bit, and then you go back to your backup, perhaps it's a USB hard drive and you find the file and restore it. RPO is the time taken to perform this procedure.
Now when it comes to DR for a business it's just on a larger scale. Don't just think that a DR event is a natural disaster more often than not; DR is instigated due to an outage of some type of connectivity, whether this is an inter site link between two offices or the main internet feed.
So what choices do we have as engineers to help us facilitate DR?
Traditional
Traditional disaster recovery plans leave organizations exposed to significant risk of extended downtime because they are laborious to setup, time consuming to maintain as they often require manual duplication of changes, and most importantly are extremely difficult to test.
Let's look at this scenario, Bob needs to update his ten front end web servers with a new patch released by the application vendors which resolves countless issues, Bob does this at Production site. He then needs to do the same thing for the ten front end web servers in the DR location; however Bob thinks you know what, I will do that after lunch. Bob gets back from lunch and has a critical issue to deal with, which takes the rest of the day. Bob resolves the critical issue, but forgets to patch the ten front end web servers in DR.
What's the net result, we have an imbalance between what's at Production and DR.
Also, how do we get the data from our Production site to our DR site? This is when we look at the next scenario software.
Software
Software replication and clustering technologies are great; would I use them for DR? Nope. Why's that you ask Craig, well the simple answer is overhead and cost.
I think this needs a little more explanation. Microsoft provides some great technology right out of the box, DFS R, SQL Replication and Exchange 2010 DAG. However, this actually means that you have to license multiple copies of the software and perhaps more importantly, configure, manage and maintain multiple copies.
Let's look at Exchange 2010, a great bit of kit; however we sometimes forget what's required to facilitate email flow at a DR site. First of all we need an anti-spam provider, with a secondary route pointing to our DR site, unless you are going to rely on a secondary MX record. We then need to have a second CAS/Hub Server at the DR site, but hold on a minute we cannot automatically fail over mail flow as the client connections are specific to a CAS server, we need to introduce a load balancer, but hey, it' can't be a single site load balancer as we need to use different internet breakouts in DR, so we need 'up the ante' and go for a global server load balancer. I think this has now entered the realms of being slightly complicated.
So what would my RPO be? Honest answer is you don't know, with the current wave of software replication and clustering technologies its best endeavours. So in the event of DR, you don't know how much data is going to be lost.
Perhaps a better question to ask is how do I even know it's working correctly? Most of the time it's let's check it manually, open up SQL to check replication, drop a file on a DFS share and check it replicates
Software replication technologies provided by Microsoft only work on a best efforts basis as you are unable to confirm how much data has been transferred across to DR site. So in the event of a DR, you do not know how much data you could potentially lose.
Another question is how do I protect my servers that are not able to use Microsoft replication technologies; the general answer is to use a software replication application. These essentially replicate a virtual machine on a pre-set schedule to the DR site on a scheduled basis.
Software replication is susceptible to application and service failures when updates or changes are applied. Often they work on snapshots which have a rather annoying fact of not getting committed and you then having to monitor your datastores on a daily basis to check for any rogue snapshots.
What about failing back once we have failed over to DR? Is it possible? Yes however, depending on the reason for the outage could mean that failback won't be possible for weeks or perhaps months. You might have to manually rebuild your entire Production infrastructure with your Domain Controllers, Exchange DAG, SQL Replication, DFS R File Replication.
With all of this in mind, I was introduced to VMware Site Recovery Manager just under two years ago, and without being biased what an awesome product.
VMware Site Recovery Manager
So why is Site Recovery Manager (SRM) so much different to traditional and software based replication? Well the answer is in its simplicity and also its ability to allow you to report on your disaster recovery effectiveness to management/directors.
We can perform a test failover whenever you like with whatever services you choose (as long as you have designed your storage layer correctly). Let's expand on this a bit.
SRM utilises either vSphere Replication<http://www.vmware.com/products/datacenter-virtualization/vsphere/replication> (included with most vSphere licenses) or Storage Based Replication. Essentially, what SRM does is allows you to take a replicated volume for example your file server which is read/write and production and read at DR. When you perform a test failover SRM sends commands to the storage layer using the Storage Replication Adapter<http://www.vmware.com/support/srm/srm-storage-partners.html> to initiate a snapshot of the Read only volume in DR. It then transforms this volume into Read/Write to allow the VM to boot and then perhaps the most important thing is that you as the 'vSphere Administrator' can choose what network the VM connects to in DR. This means that you can access the VM and make sure it works, that's pretty awesome!
So what else does SRM allow us to do?
* Change the IP Address of virtual servers on failover and failback.
* Start VM's in priority order, ensuring that subsequent VM's do not start until the higher priority VM's VMTools have started.
* Pause workflows to allow for manual user intervention.
* Run custom scripts or executable during failover or failback.
* Allow re protection and failback with ease.
This last point 'allow re protection and failback with ease' is key. Why's that, well in many SMB environments we don't always have the luxury of a dedicated SAN engineer, a dedicated vSphere engineer, a dedicated Exchange engineer, more often than not, that role belongs to you, the dedicated 'IT Engineer'
Depending on your experience you may or may not feel comfortable in taking your entire storage infrastructure and reversing its replication, I know that I for one definitely would be earning my 'bacon' if I had to do this.
SRM uses the SRA to send all of these commands essentially taking the onus away from us as the 'IT Engineer' and automates it, I mean how cool is it to be able to re protect your environment from DR to Production in three mouse clicks?
If you want to find out more about how to implement SRM and perhaps more importantly some of the key things to take into consideration, hop over to http://vmfocus.com<http://vmfocus.com/> where I have a section dedicated to this subject. Or get in touch via Twitter @vmfcraig.
Get to know Craig – Read 10 Questions With…Craig Kilborn<http://blogs.vmware.com/smb/2012/11/10-with-craig.html>
blogs.vmware.com [X] <http://blogs.vmware.com/smb/2012/11/is-srm-worth-it.html> |by VMware SMB on November 28, 2012
◆
________________________________
Original Page: http://blogs.vmware.com/smb/2012/11/is-srm-worth-it.html
Sent from Feeddler RSS Reader
A question I'm asked a lot is do I really need DR? Well reading the above statement, I hope the answer is yes, but in all reality the actual answer is, it depends. OK that is probably the most 'woolly' thing anyone in IT can say, we like hard and fast, black and white rules as engineers dammit!
For example, you may work for a company that has no on premise IT, you use a cloud based platform for your accounts, CRM and HR packages and you use hosted Exchange, SharePoint and Lync as your communication pieces, would you need DR, well the answer is probably not.
What about if you work for a company with a vSphere environment which can cater for two host failures and has redundancy on every level. This is then housed in a Tier 5 Datacenter offering 99.999% uptime, with the usual battery backed generators, diverse internet links, fire suppression systems and environmental monitoring. Connectivity is provided by diverse links to the datacentre, would you need DR then? Possibly as it depends on how the company views risk, if I was a betting man, I would say in most scenarios DR wouldn't be necessary.
Both of the above are extremes and most SMB require on premise solutions to facilitate how they work and often they don't have the budget to use datacentres and prefer to use remote offices for any DR activity.
So what does DR being with? Well two terms that you often hear banded about RTO and RPO, (great, I hear you say just what we need, more abbreviations in IT).
* Recovery Point Objective is the term used to describe how much data loss can be accepted. Let's imagine you have been working on an awesome vSphere design for the past week and you had finally nailed it, but before you hit save you get a BSOD. You are a good boy/girl scout and perform backups on a daily basis, which means that your RPO is daily.
* Recovery Time Objective is the term used to describe how long you are prepared to wait to restore data. So in the above scenario, you probably swear a bit, and then you go back to your backup, perhaps it's a USB hard drive and you find the file and restore it. RPO is the time taken to perform this procedure.
Now when it comes to DR for a business it's just on a larger scale. Don't just think that a DR event is a natural disaster more often than not; DR is instigated due to an outage of some type of connectivity, whether this is an inter site link between two offices or the main internet feed.
So what choices do we have as engineers to help us facilitate DR?
Traditional
Traditional disaster recovery plans leave organizations exposed to significant risk of extended downtime because they are laborious to setup, time consuming to maintain as they often require manual duplication of changes, and most importantly are extremely difficult to test.
Let's look at this scenario, Bob needs to update his ten front end web servers with a new patch released by the application vendors which resolves countless issues, Bob does this at Production site. He then needs to do the same thing for the ten front end web servers in the DR location; however Bob thinks you know what, I will do that after lunch. Bob gets back from lunch and has a critical issue to deal with, which takes the rest of the day. Bob resolves the critical issue, but forgets to patch the ten front end web servers in DR.
What's the net result, we have an imbalance between what's at Production and DR.
Also, how do we get the data from our Production site to our DR site? This is when we look at the next scenario software.
Software
Software replication and clustering technologies are great; would I use them for DR? Nope. Why's that you ask Craig, well the simple answer is overhead and cost.
I think this needs a little more explanation. Microsoft provides some great technology right out of the box, DFS R, SQL Replication and Exchange 2010 DAG. However, this actually means that you have to license multiple copies of the software and perhaps more importantly, configure, manage and maintain multiple copies.
Let's look at Exchange 2010, a great bit of kit; however we sometimes forget what's required to facilitate email flow at a DR site. First of all we need an anti-spam provider, with a secondary route pointing to our DR site, unless you are going to rely on a secondary MX record. We then need to have a second CAS/Hub Server at the DR site, but hold on a minute we cannot automatically fail over mail flow as the client connections are specific to a CAS server, we need to introduce a load balancer, but hey, it' can't be a single site load balancer as we need to use different internet breakouts in DR, so we need 'up the ante' and go for a global server load balancer. I think this has now entered the realms of being slightly complicated.
So what would my RPO be? Honest answer is you don't know, with the current wave of software replication and clustering technologies its best endeavours. So in the event of DR, you don't know how much data is going to be lost.
Perhaps a better question to ask is how do I even know it's working correctly? Most of the time it's let's check it manually, open up SQL to check replication, drop a file on a DFS share and check it replicates
Software replication technologies provided by Microsoft only work on a best efforts basis as you are unable to confirm how much data has been transferred across to DR site. So in the event of a DR, you do not know how much data you could potentially lose.
Another question is how do I protect my servers that are not able to use Microsoft replication technologies; the general answer is to use a software replication application. These essentially replicate a virtual machine on a pre-set schedule to the DR site on a scheduled basis.
Software replication is susceptible to application and service failures when updates or changes are applied. Often they work on snapshots which have a rather annoying fact of not getting committed and you then having to monitor your datastores on a daily basis to check for any rogue snapshots.
What about failing back once we have failed over to DR? Is it possible? Yes however, depending on the reason for the outage could mean that failback won't be possible for weeks or perhaps months. You might have to manually rebuild your entire Production infrastructure with your Domain Controllers, Exchange DAG, SQL Replication, DFS R File Replication.
With all of this in mind, I was introduced to VMware Site Recovery Manager just under two years ago, and without being biased what an awesome product.
VMware Site Recovery Manager
So why is Site Recovery Manager (SRM) so much different to traditional and software based replication? Well the answer is in its simplicity and also its ability to allow you to report on your disaster recovery effectiveness to management/directors.
We can perform a test failover whenever you like with whatever services you choose (as long as you have designed your storage layer correctly). Let's expand on this a bit.
SRM utilises either vSphere Replication<http://www.vmware.com/products/datacenter-virtualization/vsphere/replication> (included with most vSphere licenses) or Storage Based Replication. Essentially, what SRM does is allows you to take a replicated volume for example your file server which is read/write and production and read at DR. When you perform a test failover SRM sends commands to the storage layer using the Storage Replication Adapter<http://www.vmware.com/support/srm/srm-storage-partners.html> to initiate a snapshot of the Read only volume in DR. It then transforms this volume into Read/Write to allow the VM to boot and then perhaps the most important thing is that you as the 'vSphere Administrator' can choose what network the VM connects to in DR. This means that you can access the VM and make sure it works, that's pretty awesome!
So what else does SRM allow us to do?
* Change the IP Address of virtual servers on failover and failback.
* Start VM's in priority order, ensuring that subsequent VM's do not start until the higher priority VM's VMTools have started.
* Pause workflows to allow for manual user intervention.
* Run custom scripts or executable during failover or failback.
* Allow re protection and failback with ease.
This last point 'allow re protection and failback with ease' is key. Why's that, well in many SMB environments we don't always have the luxury of a dedicated SAN engineer, a dedicated vSphere engineer, a dedicated Exchange engineer, more often than not, that role belongs to you, the dedicated 'IT Engineer'
Depending on your experience you may or may not feel comfortable in taking your entire storage infrastructure and reversing its replication, I know that I for one definitely would be earning my 'bacon' if I had to do this.
SRM uses the SRA to send all of these commands essentially taking the onus away from us as the 'IT Engineer' and automates it, I mean how cool is it to be able to re protect your environment from DR to Production in three mouse clicks?
If you want to find out more about how to implement SRM and perhaps more importantly some of the key things to take into consideration, hop over to http://vmfocus.com<http://vmfocus.com/> where I have a section dedicated to this subject. Or get in touch via Twitter @vmfcraig.
Get to know Craig – Read 10 Questions With…Craig Kilborn<http://blogs.vmware.com/smb/2012/11/10-with-craig.html>
blogs.vmware.com [X] <http://blogs.vmware.com/smb/2012/11/is-srm-worth-it.html> |by VMware SMB on November 28, 2012
◆
________________________________
Original Page: http://blogs.vmware.com/smb/2012/11/is-srm-worth-it.html
Sent from Feeddler RSS Reader
Is vSphere Replication storage agnostic even when using SRM? - VMware vSphere Blog
In short: Yes, it sure is!
In this post I'll show 6 VMs being protected with vSphere Replication. 2 VMs each will reside on fibre channel data stores (EMC CX4), iSCSI data stores (Falconstor NSS Gateway), and an NFS datastore (EMC VNX5500). I'll replicate them onto different datastores, fail them over, reprotect, and fallback.
I'm always grateful to the sponsors of my storage platform for these labs – not everyone has the luxury of these setups for their lab environments! Obviously both Falconstor and EMC have great replication options on their platforms (and I use them as well!) but for these purposes I'll be using vSphere Replication to show the heterogenous support.
[NewImage]
So let's have some fun, and make sure that each VM is replicating to a completely different type of storage. In fact, let's throw in a twist and use local disk on the recovery site!
* Server1-iSCSI will be replicated to FC
* Server2-iSCSI -> NFS
* Server3-FC -> iSCSI
* Server4-FC -> NFS
* Server5-NFS -> iSCSI
* Server6-NFS -> local server disk.
Setting up the replication and the target datastore is something I've covered at length here before, so let's take that as done and just show the results. I chose each VM on each type of storage and specifically landed the target on a datastore using a different protocol as you can see here:
[NewImage]
So replication is going great – mixing and matching not only different storage vendors but utterly different protocols for the data stores as well.
This works because vSphere Replication works above the storage layer and is in fact unaware of what the storage subsystem is. It's not aware of it, doesn't care about it, and won't interact with it beyond sending blocks to a VMDK to be written.
But how does SRM handle this? With great ease and no complaints. I created a single, simple protection group and recovery plan for all these VMs together. All on different source datastore types, all with different target datastore types:
[NewImage]
And ran a test recovery against it to make sure the isolated test snapshots will work on all our VMs on all storage types. As you can see, the storage synched correctly, snapshots were all created happily, and the test run went off smoothly with VMs all over the place, on all types of data stores, using all types of storage protocols.
[NewImage]
"Test" you say? I don't trust a test, that's just a snapshot, I want to see a *real* failover! Fine, after cleanup I ran a real failover. One picture says 1000 words:
[NewImage]
So, this is great. We've taken a bunch of VMs that were scattered across a lot of different types of data stores, and failed them over to another site on different types of data stores. Let's have even more fun, and reprotect them back to the primary site. This should now set up our VMs, ready to be recovered, *back on their original storage*. I click on reprotect, and then go check out the status in the VR tab of the SRM plugin:
[NewImage]
Indeed, if you look, you can see the the iSCSI VMs are being protected to the Falconstor (which is iSCSI), the FC VMs to the CX4 (FC) and the NFS servers (one of which is currently on FC, one of which is on local disk) are being replicated back to their original location on the VNX NFS mount. vSphere Replication is smart enough to leave the original VMs behind during a failover and then use them as a target seed for reprotection when we want to fallback. In fact the reprotect will use the exact same VMDKs that were left in place in the first place, as well as the exact same replication schedule and options that we used to protect for the initial failover.
Once the reprotect is done, a fallback will put the VMs back to their original homes, on their original data stores! Replicate between different storage vendors and types, failover happily between sites (even onto local storage) then reprotect and failback to their original homes. Of course, after we fail back, I click reprotect once more and… it will again use the replicas that were already at the recovery site from our very first protection of the VMs, in the same directories, on the same data stores as before.
[NewImage]
blogs.vmware.com [X] <http://blogs.vmware.com/vsphere/2012/11/vr-srm-storage-agnostic.html> |by Ken Werneburg on November 27, 2012
◆
________________________________
Original Page: http://blogs.vmware.com/vsphere/2012/11/vr-srm-storage-agnostic.html
Sent from Feeddler RSS Reader
In this post I'll show 6 VMs being protected with vSphere Replication. 2 VMs each will reside on fibre channel data stores (EMC CX4), iSCSI data stores (Falconstor NSS Gateway), and an NFS datastore (EMC VNX5500). I'll replicate them onto different datastores, fail them over, reprotect, and fallback.
I'm always grateful to the sponsors of my storage platform for these labs – not everyone has the luxury of these setups for their lab environments! Obviously both Falconstor and EMC have great replication options on their platforms (and I use them as well!) but for these purposes I'll be using vSphere Replication to show the heterogenous support.
[NewImage]
So let's have some fun, and make sure that each VM is replicating to a completely different type of storage. In fact, let's throw in a twist and use local disk on the recovery site!
* Server1-iSCSI will be replicated to FC
* Server2-iSCSI -> NFS
* Server3-FC -> iSCSI
* Server4-FC -> NFS
* Server5-NFS -> iSCSI
* Server6-NFS -> local server disk.
Setting up the replication and the target datastore is something I've covered at length here before, so let's take that as done and just show the results. I chose each VM on each type of storage and specifically landed the target on a datastore using a different protocol as you can see here:
[NewImage]
So replication is going great – mixing and matching not only different storage vendors but utterly different protocols for the data stores as well.
This works because vSphere Replication works above the storage layer and is in fact unaware of what the storage subsystem is. It's not aware of it, doesn't care about it, and won't interact with it beyond sending blocks to a VMDK to be written.
But how does SRM handle this? With great ease and no complaints. I created a single, simple protection group and recovery plan for all these VMs together. All on different source datastore types, all with different target datastore types:
[NewImage]
And ran a test recovery against it to make sure the isolated test snapshots will work on all our VMs on all storage types. As you can see, the storage synched correctly, snapshots were all created happily, and the test run went off smoothly with VMs all over the place, on all types of data stores, using all types of storage protocols.
[NewImage]
"Test" you say? I don't trust a test, that's just a snapshot, I want to see a *real* failover! Fine, after cleanup I ran a real failover. One picture says 1000 words:
[NewImage]
So, this is great. We've taken a bunch of VMs that were scattered across a lot of different types of data stores, and failed them over to another site on different types of data stores. Let's have even more fun, and reprotect them back to the primary site. This should now set up our VMs, ready to be recovered, *back on their original storage*. I click on reprotect, and then go check out the status in the VR tab of the SRM plugin:
[NewImage]
Indeed, if you look, you can see the the iSCSI VMs are being protected to the Falconstor (which is iSCSI), the FC VMs to the CX4 (FC) and the NFS servers (one of which is currently on FC, one of which is on local disk) are being replicated back to their original location on the VNX NFS mount. vSphere Replication is smart enough to leave the original VMs behind during a failover and then use them as a target seed for reprotection when we want to fallback. In fact the reprotect will use the exact same VMDKs that were left in place in the first place, as well as the exact same replication schedule and options that we used to protect for the initial failover.
Once the reprotect is done, a fallback will put the VMs back to their original homes, on their original data stores! Replicate between different storage vendors and types, failover happily between sites (even onto local storage) then reprotect and failback to their original homes. Of course, after we fail back, I click reprotect once more and… it will again use the replicas that were already at the recovery site from our very first protection of the VMs, in the same directories, on the same data stores as before.
[NewImage]
blogs.vmware.com [X] <http://blogs.vmware.com/vsphere/2012/11/vr-srm-storage-agnostic.html> |by Ken Werneburg on November 27, 2012
◆
________________________________
Original Page: http://blogs.vmware.com/vsphere/2012/11/vr-srm-storage-agnostic.html
Sent from Feeddler RSS Reader
Wednesday, November 21, 2012
VMware Innovate magazine edition available for download!
Internally at VMware we have this cool magazine called "Innovate". I am part of the team which is responsible for VMware Innovate. I noticed this tweet from Julia Austin and figured I would share it with all of you. This specific edition is about RADIO 2012, which is a VMware R&D innovation offsite. (So looking forward to RADIO 2013!)
Check out #VMware<https://twitter.com/search/%23VMware>'s Innovate Magazine.Usually internal only, but we wanted to share this one with our community! ow.ly/fijfP<http://t.co/3zntpFLE>
— Julia Austin (@austinfish) November 14, 2012<https://twitter.com/austinfish/status/268825473021255682>
There is some cool stuff to be found in this magazine in my opinion. Just one of the many nuggets, did you know VMware was already exploring vSphere FT in 2001? Just a nice reminder of how long typical engineering efforts can take. Download the magazine now<http://t.co/3zntpFLE>!
Ganesh Venkitachalam presented "Hardware Fault Tolerance with Virtual Machines" (or Fault Tolerance, for short) at the "Engineering Offsite 2001." This was released as a feature called Fault Tolerance for vSphere 4.0.
Be Sociable, Share!
[image]
yellow-bricks.com [X] <http://www.yellow-bricks.com/2012/11/19/vmware-innovate-magazine-edition-available-for-download/> |by Duncan Epping on November 19, 2012
◆
________________________________
Original Page: http://www.yellow-bricks.com/2012/11/19/vmware-innovate-magazine-edition-available-for-download/
Sent from Feeddler RSS Reader
Check out #VMware<https://twitter.com/search/%23VMware>'s Innovate Magazine.Usually internal only, but we wanted to share this one with our community! ow.ly/fijfP<http://t.co/3zntpFLE>
— Julia Austin (@austinfish) November 14, 2012<https://twitter.com/austinfish/status/268825473021255682>
There is some cool stuff to be found in this magazine in my opinion. Just one of the many nuggets, did you know VMware was already exploring vSphere FT in 2001? Just a nice reminder of how long typical engineering efforts can take. Download the magazine now<http://t.co/3zntpFLE>!
Ganesh Venkitachalam presented "Hardware Fault Tolerance with Virtual Machines" (or Fault Tolerance, for short) at the "Engineering Offsite 2001." This was released as a feature called Fault Tolerance for vSphere 4.0.
Be Sociable, Share!
[image]
yellow-bricks.com [X] <http://www.yellow-bricks.com/2012/11/19/vmware-innovate-magazine-edition-available-for-download/> |by Duncan Epping on November 19, 2012
◆
________________________________
Original Page: http://www.yellow-bricks.com/2012/11/19/vmware-innovate-magazine-edition-available-for-download/
Sent from Feeddler RSS Reader
Free Elearning Course - VMware vCenter Site Recovery Manager 5.1 Fundamentals
The SRM Essentials free elearning (self-paced, 3 Hours) training course equips experienced VMware vSphere administrators with the knowledge to install, configure, and manage VMware vCenter Site Recovery Manager (SRM) 5.1. This elearning also equips vSphere administrators with the knowledge to assist in disaster planning and test disaster recovery plans with SRM. This course introduces different storage replication options and focuses on vSphere Replication.
After completing the course, you should be able to:
* Install SRM 5.1
* Connect the sites
* Configure inventory mappings in SRM
* Configure placeholder datastores
* Configure datastore mappings
* Configure vSphere Replication-based protection groups in SRM
* Create, edit, execute, test, and remove a recovery plan in SRM
* Discuss reprotect and failback
* Describe SRM alarms
* List administrative tasks
The course consists of three modules:
Introduction to VMware vCenter Site Recovery Manager (SRM) provides an overview of the challenges that organizations face when a disaster occurs, and how SRM acts as the best disaster recovery product. This module also discusses the benefits that organizations can realize by utilizing the new features that SRM 5.1 provides.Setting up Protection is the second module, that demonstrates how to install VMware vCenter Site Recovery Manager and set up the protected site. This module discusses how to prepare for an SRM deployment; install SRM; configure SRM; configure vSphere Replication; and create protection groups. Managing Disaster Recovery is the last module that demonstrates how to create, configure, test, and run disaster recovery plans. This module discusses features that are new in version SRM 5.0 and later, such as reprotection and automated failback. Finally, this module also discusses SRM alarms and some administrative tasks.
http://mylearn.vmware.com/mgrReg/courses.cfm?ui=www_cert&a=det&id_course=154960
◆
________________________________
Original Page: http://feedproxy.google.com/~r/Ntpronl/~3/8656VlERFak/2223-Free-Elearning-Course-VMware-vCenter-Site-Recovery-Manager-5.1-Fundamentals.html
Sent from Feeddler RSS Reader
After completing the course, you should be able to:
* Install SRM 5.1
* Connect the sites
* Configure inventory mappings in SRM
* Configure placeholder datastores
* Configure datastore mappings
* Configure vSphere Replication-based protection groups in SRM
* Create, edit, execute, test, and remove a recovery plan in SRM
* Discuss reprotect and failback
* Describe SRM alarms
* List administrative tasks
The course consists of three modules:
Introduction to VMware vCenter Site Recovery Manager (SRM) provides an overview of the challenges that organizations face when a disaster occurs, and how SRM acts as the best disaster recovery product. This module also discusses the benefits that organizations can realize by utilizing the new features that SRM 5.1 provides.Setting up Protection is the second module, that demonstrates how to install VMware vCenter Site Recovery Manager and set up the protected site. This module discusses how to prepare for an SRM deployment; install SRM; configure SRM; configure vSphere Replication; and create protection groups. Managing Disaster Recovery is the last module that demonstrates how to create, configure, test, and run disaster recovery plans. This module discusses features that are new in version SRM 5.0 and later, such as reprotection and automated failback. Finally, this module also discusses SRM alarms and some administrative tasks.
http://mylearn.vmware.com/mgrReg/courses.cfm?ui=www_cert&a=det&id_course=154960
◆
________________________________
Original Page: http://feedproxy.google.com/~r/Ntpronl/~3/8656VlERFak/2223-Free-Elearning-Course-VMware-vCenter-Site-Recovery-Manager-5.1-Fundamentals.html
Sent from Feeddler RSS Reader
Thursday, November 1, 2012
Considering VSA for ROBO? Please read this! - VMware vSphere Blog
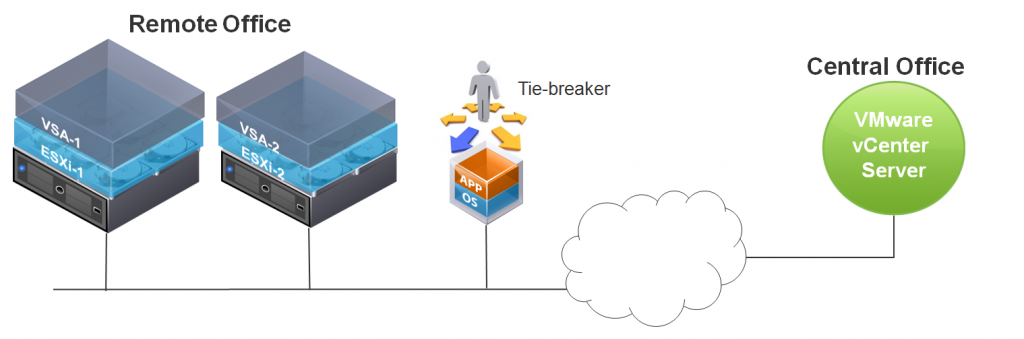
After fielding a number of questions around this topic recently, its come to my attention that there is a misunderstanding on how to implement the vSphere Storage Appliance (VSA) for certain ROBO solutions. The requirement around the tie-breaker code (VSA Cluster Service) is either misunderstood or misinterpreted when it comes to 2 node VSA deployments at remote office/branch office (ROBO) sites.
Let's be clear about it now – the VSA needs 3 votes in order to function correctly as a cluster. In a 3 node VSA deployment, this is not an issue since each node gets a vote. In a 2 node VSA deployment, the third vote is handled by the VSA Cluster Service aka the tie-breaker code.
Now, in standard (non ROBO) 2 node VSA deployments where the vCenter is located in the same datacenter as the VSA, the VSA Cluster Service can exist on the vCenter server. During VSA installation, you simply provide the IP address of the vCenter server for the VSA Cluster Service.
However, in ROBO deployments, things are a little different. In these deployments, the vCenter server is typically located at a central office, and the 2 node VSA is deployed at a remote office. The third vote (tie-breaker code) must also be located at the remote office/branch office. To cater for this, we allow the VSA Cluster Service to be decoupled from vCenter and installed in a VM. The VM can be running on a non-VSA ESXi host or Workstation at the branch office. We cannot have it run on the ESXi hosts involved in the VSA cluster because if we lost the host on which the tie-breaker VM was running, we lose 2 votes, and thus the cluster quorum. So it must exist outside of the VSA.
[http://blogs.vmware.com/vsphere/files/2012/10/diag-1024x339.png]<http://blogs.vmware.com/vsphere/files/2012/10/diag.png>
VMware provides VSA Cluster Service installation documentation for the different platforms that we support. Currently there is Standalone VSA Cluster Service for Linux and a Standalone VSA Cluster Service for Windows. The VSA Cluster Service platform must be on the same subnet as the VSA cluster members.During the install, then installer will ask for details of which host has the tie-breaker code, so the VSA Cluster Service must be installed first. The VSA Installation wizard will then audit this, making sure that it can reach and communicate to the VSA Cluster Service code.
Please make sure you take into account the requirement for the VSA Cluster Service at the remote office/branch office site when designing or achitecting 2 node VSA ROBO solutions.
Get notification of these blogs postings and more VMware Storage information by following me on Twitter: @VMwareStorage<http://twitter.com/#%21/vmwarestorage>
blogs.vmware.com [X] <http://blogs.vmware.com/vsphere/2012/11/considering-vsa-for-robo-please-read-this.html> |by Cormac Hogan on November 1, 2012
◆
________________________________
Original Page: http://blogs.vmware.com/vsphere/2012/11/considering-vsa-for-robo-please-read-this.html
Let's be clear about it now – the VSA needs 3 votes in order to function correctly as a cluster. In a 3 node VSA deployment, this is not an issue since each node gets a vote. In a 2 node VSA deployment, the third vote is handled by the VSA Cluster Service aka the tie-breaker code.
Now, in standard (non ROBO) 2 node VSA deployments where the vCenter is located in the same datacenter as the VSA, the VSA Cluster Service can exist on the vCenter server. During VSA installation, you simply provide the IP address of the vCenter server for the VSA Cluster Service.
However, in ROBO deployments, things are a little different. In these deployments, the vCenter server is typically located at a central office, and the 2 node VSA is deployed at a remote office. The third vote (tie-breaker code) must also be located at the remote office/branch office. To cater for this, we allow the VSA Cluster Service to be decoupled from vCenter and installed in a VM. The VM can be running on a non-VSA ESXi host or Workstation at the branch office. We cannot have it run on the ESXi hosts involved in the VSA cluster because if we lost the host on which the tie-breaker VM was running, we lose 2 votes, and thus the cluster quorum. So it must exist outside of the VSA.
[http://blogs.vmware.com/vsphere/files/2012/10/diag-1024x339.png]<http://blogs.vmware.com/vsphere/files/2012/10/diag.png>
{kind=link}
{kind=link}
VMware provides VSA Cluster Service installation documentation for the different platforms that we support. Currently there is Standalone VSA Cluster Service for Linux and a Standalone VSA Cluster Service for Windows. The VSA Cluster Service platform must be on the same subnet as the VSA cluster members.During the install, then installer will ask for details of which host has the tie-breaker code, so the VSA Cluster Service must be installed first. The VSA Installation wizard will then audit this, making sure that it can reach and communicate to the VSA Cluster Service code.
Please make sure you take into account the requirement for the VSA Cluster Service at the remote office/branch office site when designing or achitecting 2 node VSA ROBO solutions.
Get notification of these blogs postings and more VMware Storage information by following me on Twitter: @VMwareStorage<http://twitter.com/#%21/vmwarestorage>
blogs.vmware.com [X] <http://blogs.vmware.com/vsphere/2012/11/considering-vsa-for-robo-please-read-this.html> |by Cormac Hogan on November 1, 2012
◆
________________________________
Original Page: http://blogs.vmware.com/vsphere/2012/11/considering-vsa-for-robo-please-read-this.html
Subscribe to:
Posts (Atom)